昨天帶各位使用MaelPy來針對DCGAN進行超參數的最佳化並執行了程式,今天就來看看結果吧!
昨天的程式執行結果如下表所示:
| 超參數名稱 | 最佳超參數值 |
|---|---|
| 生成器學習率 | 2.95685686e-04 |
| 判別器學習率 | 3.80815357e-04 |
| 生成器第一層卷積層的神經元數量 | 32 |
| 判別器第一層卷積層的神經元數量 | 64 |
| 生成器卷積核大小 | 3 |
| 判別器卷積核大小 | 4 |
| 判別器LaekyReLU斜率 | 0.25 |
| 最佳適應值 | 8.435876443982124 |
另外以下是最佳化的收斂曲線: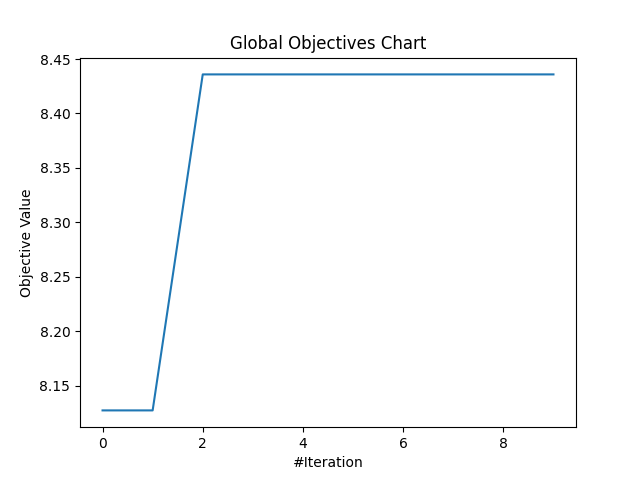
結果看起來和之前一樣還是差不多,其實並不優秀,不過大概有幾個原因,這部分就跟第21天文章介紹的相同,因為雖然更換了使用的模組與演算法,不過訓練結果的問題通常不會差太多,但使用啟發式演算法也有可能會有演算法參數設定的問題:
在實務應用上,需要注意若不確定最佳化程式是否有問題可以先使用較低迭代次數,與較低訓練次數,先以時間消耗少的方式完整跑過程式,沒問題之後再使用完整的設定來執行程式。
在第9天我有介紹一些其他可以使用最佳化的模組,不過當時我漏掉了兩個,分別為以下的函式庫。這兩個都是機器學習與深度學習的大咖模組中提供的最佳化方式,在不了解其他演算法的情況下,只想趕快交差也可以使用看看這兩個函式庫來簡單的針對自己的模型進行最佳化。
目前也有許多人會使用Pytorch,不過我印象中Pytorch並沒有內建超參數最佳化的工具,若有需要使用的話可以參考我這系列前面的文章,使用Optuna或者MealPy來進行參數的最佳化。
這次使用MealPy進行DCGAN的最佳化,啟發式演算法的差異就是除了迭代次數以外每次迭代都還需要完整跑完群體中所有成員的解,所以會造成程式執行的更久。不過通常這樣更廣泛的搜索最佳解時也會比較著重於尋找偏向全局最佳的地方,無論使用哪個模組,哪個演算法,基本上都還是有優缺點,所以就需要斟酌看看啦。
這次鐵人賽的程式介紹就到這邊為止,雖然還有許多可以提及的東西,不過30天一轉眼就即將結束了,最後兩天我會簡單的介紹最佳化演算法在AI模型的一些其他應用以及這次比賽的心得。接下來也要趕快去拯救我的課業了哈哈,希望未來還有時間跟機會可以整理我所學的程式技巧並向各位分享。

